
こんにちは。ベトナム からベーシックのエンジニア@yuyuvn です。
からベーシックのエンジニア@yuyuvn です。
ソフトウェアでは不具合はバグとよばれます。どんなシステムでもバグがあります。
最近、小さいサービスでもフェイスブックのような大きいサービスでもよく不具合が発生しています。これは一体、なぜでしょうか?

バグの原因
2013年のIBMの記事の通り、ソフトウェアはどんどん複雑になりつつあるということがわかります。現時点でもこの視点が間違いないでしょうか?ソフトウェアはどんどん多くのことができるようになり、ユーザの操作が少なくなります。使用用途が増えると、ソフトウェアの複雑さも高くなります。ソフトウェアは複雑になる程、修正が難しくなります。依存関係が増えて、複雑さも増して、結果としてデバッグが大変な作業になってしまいました。「Judge Business School of the University of Cambridge」の大学の研究によると、開発のコストの30%がバグ対応、開発時間の50%は新しい機能を実装ではなくてバグの修正です。
どうやってデバッグしやすくするか
普段のデバッグには二つのフェーズがあります。調査と修正です。調査のほうが難しく時間もかかります。そのため、Googleには「バグを隠すより見つかりやすい方がいい」と言う文化があるほどです。私もそうだとおもいます。もしテストフェーズでたくさんのバグができたら本番のプロジェクトのバグが少なくなることです。
プログラミング言語は大きく分けて2つの種類があります。コンパイラ型とインタープリタ型です。コンパイラ型の場合はコンパイルするとき見つかったバグが多ければ多いほどいいです。なぜならコンパイルする時点、トレースバックとか再現させることを考える必要はないから修正するのはすごく簡単です。
例えば以下のCのコードがあって
void main() {
int a;
int b = 1;
if (b == 1) {
a = 1;
} else {
a = 2;
}
printf("a = %d", a);
}
新しいロジックを追加する
void main() {
int a;
int b = 1;
if (b == 1) {
a = 1;
} else if (b == 2) {
// 他のロジック
} else {
a = 2;
}
printf("a = %d", a);
}
これはコンパイルできるがaがnullになってしまいます。これはバグが発生する可能性が高いです。
Rustで書き直します。以下の書き方を見ましょう。
fn main() {
let mut a;
let b = 1;
if b == 1 {
a = 1;
} else if b == 2 {
// 他のロジック
} else {
a = 2;
}
println!("a = {}", a);
}
これはコンパイルしたらエラー発生します。これはすぐ確認して修正することができるため良いコードです。
|
| println!("a = {}", a);
| ^ use of possibly uninitialized `a`
他のケースで、例えばhoge、piyo、fugaというメソッドがあってhogeの中でpiyoが呼ばれる、piyoの中でfugaが呼ばれる。もしfugaのメソッドの中にバグがあったらhoge、piyoも正常に動作しないことでしょう。これはunitテストでカバー出来るが、もしカバー出来ない場合はruntimeで発生する時はhogeの中の時か、piyoの中時でもあります。デバッグではトレースバックが必要です。Rust言語だったらメソッドの定義をするときどんなparamの値があるか確認するコードが必要です。そうするとfugaのバグがあったら最悪でもpiyoでエラーが発生します。hogeで発生することはないです。ただ、コードはSOLID原則を必ず守らないと効果がありません。特にSOLIDのS(単一責務の原則)です。
バグ発生率はどうしてもゼロにすることは出来ない。バグが発生した時にどうすれば良いでしょうか?
理想的には、不具合がある箇所をソフトウェアが自動的に修正することです。ただ今の技術段階ではまだ難しいです。なので、不具合が発生した時点の情報を出来るだけ集めてレポートを担当者に送って人間で修正するというフローは悪くないです。
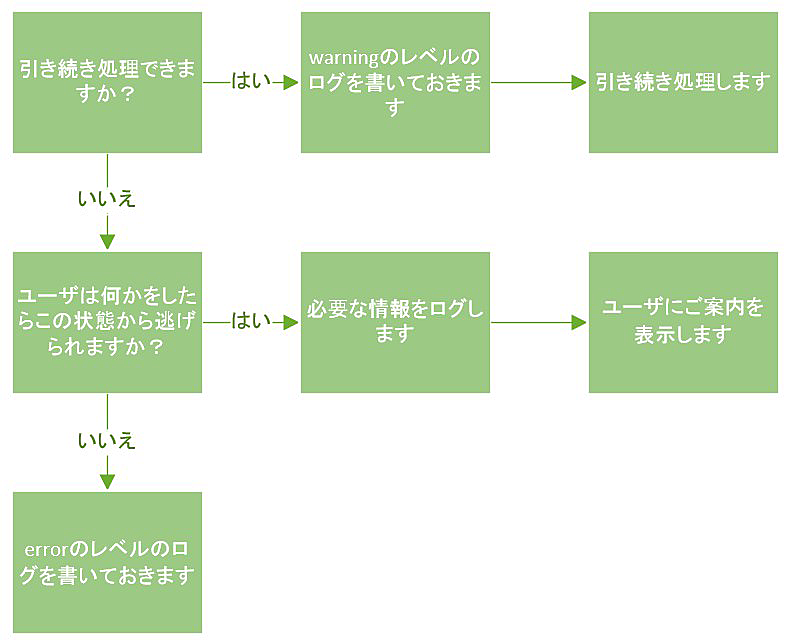
保存しておく障害時のログ情報は多ければ多いほどいいですが、その保存した生のログファイルは人間が読むものではないです。トラブル発生時に必要な情報を自動的に判断し、まとめてレポートとして人に送ることで調査時間を節約できます。
まとめ
新しいコードを反映しなければ新しいバグは発生しませんし、ユーザ数が増えなかったらスケールは必要じゃありません。バグを恐れずに開発できたら最高です。
エンジニアたちはバグを食べざるを得ず、逃げることなどは出来ないが、ちゃんと切って、煮て、お皿に盛れば、食べてもお腹が痛くなることはないでしょう。