
ベーシック アドベントカレンダー 7日目です。
306 と申します。
コアなファンのために今の経歴を説明しますと
ferret One 開発 → SREチーム発足(ソロ) → ferret 開発 となっております。
今日は Web Components ではなく、
ferret のインフラなどについて話していければと思います。
ferret は 2019年 8月に大規模リニューアルを行いました。
国内最大級、42万5千人の会員を持つWebマーケティングメディア「ferret」がリニューアル
マーケターの求人特化の記事広告「job ferret」を
正式リリース!
左がリニューアル前で、右がリニューアル後の今の ferret になります。
左のページに見覚えのある人も多いではないでしょうか。
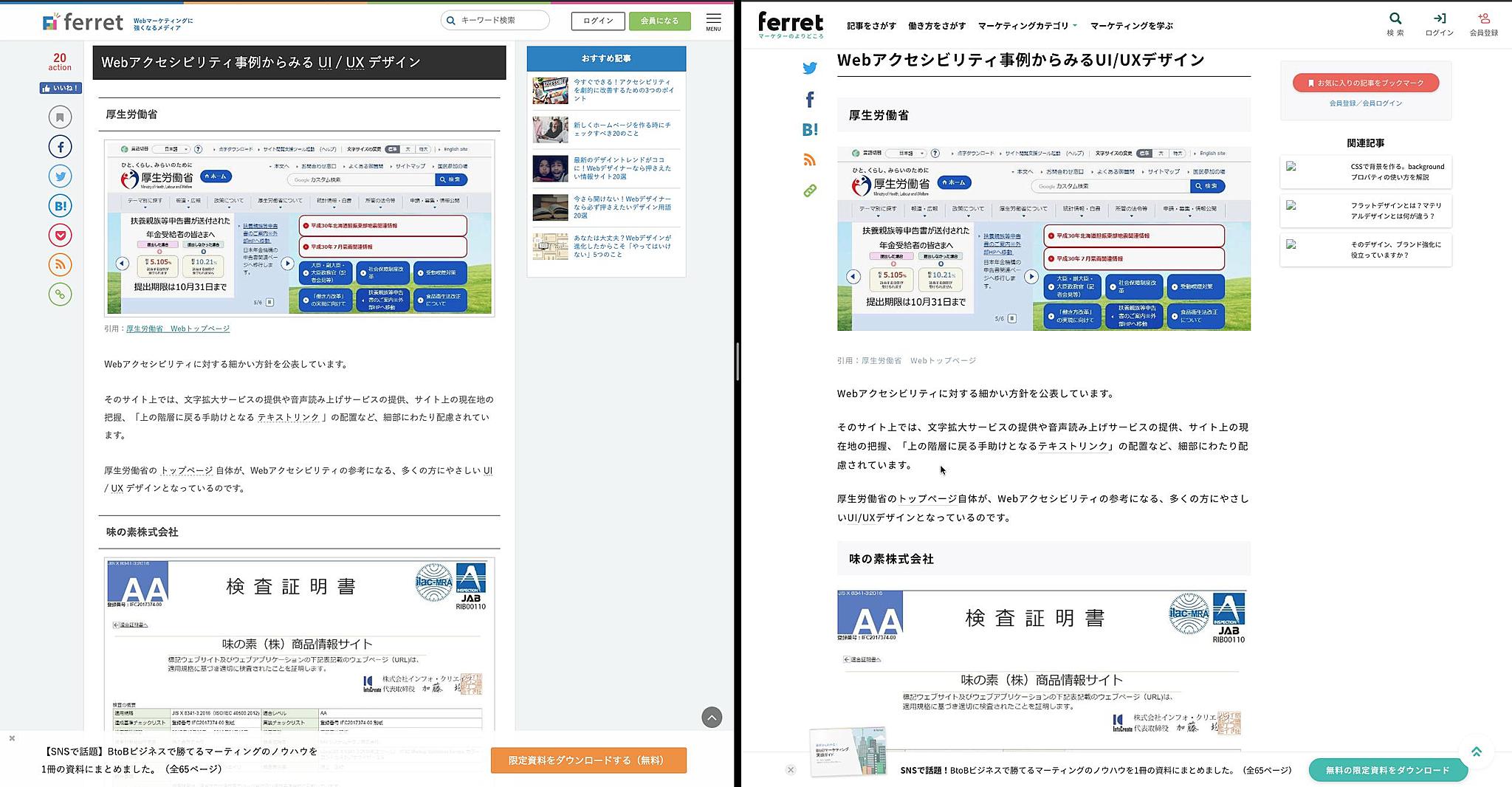
リニューアル内容としては、全てフルスクラッチで開発を行いました。
古くからやっているサービスなので
見た目だけ変えたように思えるかもしれませんが
システムごと一新されております。
その結果インフラも最先端な内容となりました。
| 内容 | リニューアル前 | リニューアル後 |
|---|---|---|
| Server | EC2 | EKS on EC2 |
| DB | MongoDB on EC2 | RDS(Aurora) |
| Redis | ElastiCache(Redis2互換) | ElastiCache(Redis5互換) |
旧 ferret では DB に MongoDB を採用しており、EC2で自前で運用しておりました。
そのため、プライマリーで稼働している EC2 のリタイア通知に恐怖したり、Linux カーネルのアップデート当てるための再起動や MongoDB のアップデートどうやっていくか・・・など様々な保守運用まつわる課題に悩まされていました。
今回のリニューアルで Aurora に移行でき、保守周りを AWS に投げられる幸せや保守コストの削減を実感できております。
現在だったら Document DB がありますが、リニューアルを検討した時にはまだ発表されていなかったのと、mongoid が開発する上で ActiveRecord とは違う挙動をするので辛い部分が多く、 RDBMS を使いたかったという理由もあり結局採用されなかったんじゃないかなと思います。
前置きが長くなりましたが、 今日は EKS について話していこうと思います。
ferret では EKS を使って Rails アプリを動かしております。
ベーシックでは初の本番環境が k8s で動くサービスになっております。
(余談ですが、 k8s のことを弊社では 「けーはち」とよんでいます。結構かわいい言い方で気に入ってるので他のところでも広まればと思います。)
まず EKS を採用した理由なんですが、弊社で k8s のノウハウや知見を深めたいからというのが大きいです。
コンテナを運用する場合、AWS の場合 ECS という選択肢もありますが、弊社で別プロダクトで ECS を使っており、そことの比較も兼ねて、使ってみたいという気持ちがありました。
ただ運用して気づいたんですが、 ferret では特にマイクロサービスをやっているわけでもなく、 Pod も App と Worker の2つだけなので ECS でも良かったのかなと思います。
あと、 k8s が好きなエンジニア(先輩)がいたのも大きいです。先輩がいなければ k8s の学習スピードが著しく落ちていたと思います。
EKS のいいところは色んな所で話されていると思います。
今日は運用してみて気づいた課題点について話していければと思います。
EKS にしても結局 EC2 の保守が残りつらい
最初に嘘を書いてしまったことをお詫びします。
なぜなら 最近 EKS on Fargate が登場したので、この課題はなくなるかもしれません。
ですがまだ執筆当時はまだ登場していなかったのでご了承ください・・・。
ECS と違い EKS はコンテナを EC2 でしか動かすことができません。
コンテナに移行したので、 EC2 から開放されると思っていましたがそういうわけにはいきませんでした。
弊社で起こった EC2 起因の障害事例としては、
ある日、全 Node が NotReady 状態になり、Webサイトが見れない状態に陥りました。
k8s やっている人ならこの危機感がわかると思いますが、
Node というのは Pod を動かす場所です。 EC2 がそれにあたります。
つまり今回は k8s からみた場合 EC2 が全て死んでいるので、 Pod を配置できない状態になっているわけです。
当時は ロールバックの仕方も知らない状態だったので、
とりあえず Webコンソールから EC2 を再起動して Reday にしていき、
NotReady になった Node をまた再起動して・・・を繰り返して
Revertコミットののイメージがプッシュされるなんとかみれる状態にしていました。
(EC2の再起動だけでどうにかできるのがコンテナのいいところですね)
原因としては、アプリケーションコードでメモリーを馬鹿食いするコードを書いてしまい、
kubelet に OOMが発生し、k8s との通信ができなくなったのが原因でした。
当時はC5.large インスタンス(RAM 4.0GiB)に
アプリケーション用 Pod の resources.limits.memory を 3.5Gi で設定していました。
こうすれば k8s からメモリを使い果たしたコンテナは勝手に kill され、一見良さそうに見えますが
実際Node 上の Pod はアプリケーション以外にもいます。
aws-node, coredns, kube-proxy,
helm で入れた
datadog, cloudwatch...etc...
とこのようにいっぱいいるわけです。
ここでは自分たちでは意識していないPod群 通称 野郎Pod と呼びますが
野郎Podだけで 1.5Gi も消費している状態です。
おわかりになったかと思いますが、
野郎Pod もそこそこメモリを使っており。
アプリケーションPodが 3.5Gi 使う前から OOM がすでに発動している状態でした。
そのため、最終的に kubelet OOM されてしまう事態を招いてしまいました。
対策として。
インスタンスをもっとメモリのあるものに強化(m5.large)
各Pod の総容量を確認して、問題ない量に設定
またすぐ復旧できるようにロールバックの手順を確認
ということを行いました。
この問題をなくすためには、Pod ごとに動く Node が必要になってしましますが
それを叶えるのが Fargate であり早く出ないかなぁと思っています・・・。
EKS におけるネットワークデザインパターンがわからなくてつらい
私がネットワーク設計に固執しすぎてるだけかもしれませんが、
Nodeが現状Poublic Subnet にしかおけず、
Private Subnet におけなかったりします。
これが今までの私のネットワーク設計と合わず困っております。
Appサーバーなら Private Subnet に置きたいのですが今はそうでもないのでしょうか?
ここらへんの設計パターンを知りたいと思っています。
k8s のアップデートがつらい
k8s のアップデートは大きく分けて Node と マスターの2つがあります。
まずは Node です。
Node をどう作るかによってここのアップデートの方法が変わってきますが、
ferret では CloudFormation を使って作成しております。
Nodeのアップデートは基本 AWS が EKS 専用 AMI を配信しているので、
CloudFormation で AMI ID を書き換えてローリングアップデートしているようにしています。
(やる前後で ClusterAutoScaler の Scale をいじらないといけないので自動化はできていません)
ただこの AMI が頻度で更新されるのか謎で、きちんとセキュリティアップデートはやっているのか不安になるときがあります。
自分たちで毎日 yum update を走らせた AMI を作ることも考えましたが、運用保守コストが高いのでやめております。
今は提供されている AMI をそのまま使っていますが AMIの更新があった場合に通知などが現状ないので、
EKSを運用されている皆さんはどうされているのか気になったりしています。
と書いていたら、先日 Managed Node が出てきてこの課題が解消できそうな感じがしております。
最後にマスターです。
ferret は k8s v1.13 で動いています。
先日 EKS で Managed Node という便利なものが出ましたが
1.14以降の対応なのでまずアップデートしなければいません。
ですが、1.14 のアップデートは大変です。
AWSのドキュメントを読むとやり方は書いてあるのですが、
結構複雑な感じです。
理想は新しいマスターを作ってそこから Node を作るのがいいと思うのですがすでに動いている Web サービスを落とすことなくこれをやるのは結構大変でどうしたものかと悩んでおります。
あと EKS 自体のアップデートもあります。
最近になって、 Managed Node, EKS on Fargate も出てきましたし、
もうすぐ k8s v1.15 の対応も来そうです。
ferret は現在 4人体制で開発を行っていますが
先々月までは、3人体制で開発を行っていました。
EKSとk8s の機能の検証・保守はアプリケーション開発の片手間に触っていられるほど簡単なものではなく、
1人分のリソースを消費しています。
人が多いと関係ないのかもしれませんが、少人数で k8s を運用するとなるとこの問題は結構大きく
現在は私が主に k8s の面倒を見ている状態なのでどうにかしたいと思いつつ
アプリケーション開発もやることがたくさんあり、
アプリケーション開発以外ににリソースが割り振れないところがつらいです。
といろいろ辛いところを書きましたが、
本番を k8s で使っている人〜で挙手できるようになったのは嬉しいですし
スケールも簡単にでき、急なアクセス数増にも対応することができました!
k8s の柔軟なインフラ構築力と宣言的な構成管理により
インフラ周りも GitHub で管理できとても喜んでいます。
これから k8s を運用する人に k8s を今後運用していく上でどういった問題が起こるのか
認識できる一歩になればなと思います。
最後まで読んでいただきありがとうございました!